The answers to the questions below are supposed to feel uncomfortable but, before you indulge those feelings, give an earnest go of it, first.
- How much information is already out there about you, your family, your company, your employees, etc?
- How much of it do you control and how much of it do you not control?
- How much of it could be used against you?
These are tough questions but important ones worth asking.
What we can do about the answers we uncover? Waiting to ask these questions after it’s too late is more stressful, more expensive, and less effective, nowhere near as valuable or satisfying.
The Creepy News
Criminal hackers are very good at collecting information that helps them choose their targets. They use Open Source Intelligence gathering, known as OSINT, tactics that include scouring every possible source of information to gather intel about potential targets. Criminals are generally going to find the path of least resistance.
Criminals assemble all the bits and pieces (unstructured data) into insights (structured data) about our work and life that can be used to achieve potentially evil goals, from straight-up blackmail to breaking into our office or home network, to tricking us into countless forms of fraud, and other wild, fiction-esque scenarios that no one would believe if they didn’t live through it themselves.
So please don’t post a selfie on Instagram while at your desk at work with a password posted on a sticky in view behind you, for example. Don’t post pictures anywhere that makes it easy for someone to subvert otherwise effective security and privacy controls that are there to protect you.
Here’s another OSINT fun fact to be aware of: your followers and the accounts you follow on social media can provide clues for targeting you, too, especially if you’re like most people who follow local news/radio stations where they live, their kids school, church, hobbies, and more. That’s what private lists are for. Raise the cost for criminals. Don’t make yourself an easy choice for them.
Information About You Is Already Out There
There is a big difference between the information I control about myself and the information I don’t. For example, if I have a personal blog that I host and control myself, I can control the kinds of information that can be easily harvested. It is valuable to control information about our identity.
This point bears repeating because it’s a commonly overlooked practice. If you don’t control any information about your online identity, your online identity is much easer to steal. Especially if you don’t have a common name. Those with common names have a blessing and a curse to tackle in this context: they might blend in with a bazillion others with the same name, however, they also blend in, which can make it easy to steal their identity.
Owning our online identities is more important than most people realize, especially for those who haven’t been through the experience of an identity theft. It’s always easy to sell house fire insurance to someone standing there watching their house burn down.
If you have a personal blog that you don’t control, that isn’t self-hosted, or only use social media like Facebook, Instagram, Twitter, etc., you have no control over that information anymore. You don’t even own it anymore once you upload it. Be mindful of what you use those platforms for. They’re busy selling your contributions behind the scenes to an unknown number of third parties and doing zero to help protect your online identity from those who might abuse it.
The Good News
OSINT tools, tactics, and strategies can (and should) be used for good, too, to improve your security and increase your privacy. You don’t have to be a skilled hacker to learn what might be used against you, your family, your friends, your team, or your organization.
You can gather and synthesize information relevant to you and use it to educate and improve yourself, your family, your team and what, why, and how they share information about themselves and/or your organization online. These kinds of exercises are valuable training tools for forward-thinking organizations who set out to build a security-aware culture with intention.
A Fundamental OSINT Method: “Web Scraping”
What’s “Web scraping”?
Web scraping is a method collecting information from the Web either manually or using automated tools. Any content that can be viewed on a device using a browser can be “scraped”, including files that can be downloaded and much, much more that’s not at all obvious to everyday people.
Using more sophisticated methods, such as accessing undocumented APIs, RSS feeds, JSON endpoints, and inspecting network traffic, etc., anyone so inclined can harvest massive amounts of information quickly.
Can it be prevented? Sort of. Web scraping can be prevented using defensive tactics and strategies but some of these, especially when implemented incorrectly, can be defeated with some creative improvisation.
Why does Web scraping exist?
Web-scraping is most commonly used for its utility to detect malfunctioning components of a website, such as an API that’s not working right. APIs are the hidden machinery that powers sites with added functionalities that are typically data-driven. Most system administrators typically overlook this hidden machinery. We know this because it’s not uncommon for APIs and other relevant data feeds to change unexpectedly overnight.
When APIs change in some major way and no one’s paying attention, they break sites, which is why someone only notices when a site goes down or starts to have some unusable issue that creates real incentive for someone to resolve it quickly. Web scraping is useful for finding out what’s broken and how it can be fixed. So, Web-scraping, as a tool, comes from legit purposes. Like so many things that are dangerous, many of them were first intended to help not harm. So it is with Web scraping.
Structured vs. Unstructured Data
Most of the information we’re used to seeing online is organized. When we use sites and apps, these are designed to present us with structured data, data that has already been arranged in a way for us to quickly get value from it.
Data mined using Web scraping tools, either manual or automated, is unstructured. It’s raw and unfiltered. What does that mean?
Imagine a spreadsheet with random ingredients and steps for a recipe copied and pasted all over the place, placed in random cells willy-nilly without any rhyme or reason. Without organizing all of our information about the recipe into specific rows, the information isn’t very useful but rather only confusing. We wouldn’t be able to tell ingredients from steps! If everything is just jumbled together we might not even be able to tell the spreadsheet had anything to do with cooking. That’s called unstructured data.
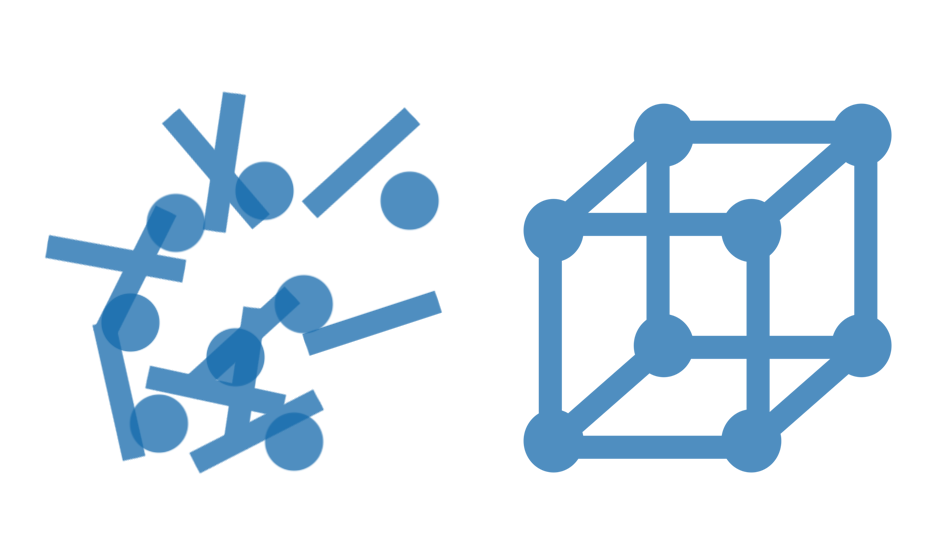
To create structured data out of our unstructured data, maybe we’d use some rows to specifically list all of our ingredients in an orderly fashion. Other rows, maybe below the ingredients, would outline our steps.
By making it structured, we add tremendous value to it. This takes time and know-how but is easy to do when you’ve had some experience. That isn’t to say unstructured data isn’t valuable. It is extremely valuable because when mined from multiple sources it can be structure in new ways to create new connections, contexts, and meaning.
Many criminals are good at turning unstructured data into structured data, which is why it takes some specialized knowledge, and discussions like this, to help more audiences understand what’s going on out there. We can ignore this information or use it to our advantage to minimize the likelihood that we will be an easy target.
Is it legal?
Yes. And no. It varies a great deal depending on the part of the world you’re in, the type of scraping being done, your intent, etc. Besides this complexity, rules governing these activities are relatively new and haven’t had much experience in the law or to the people skilled in the law. Having a set of rules is one thing. Detecting violations and enforcing them are quite another.
Regardless, be cautious and respectful if you intend on experimenting to learn more because you could potentially get yourself into trouble if you choose to use these kinds of tools in ways that violate terms of service and fair use. We share the information about OSINT and Web scraping here explicitly for learning purposes only. I accept no liability if you do something else with it.
Learning More
Below are links that lead to resources for learning much more about this stuff than most people will likely ever be interested in but it’s useful if you’re the curious type who needs to understand how to take steps to make these activities more challenging for would-be criminals.
Imagine the following knowledge as a better lock for your bike, the type that will make criminals look elsewhere for an easier target to steal. Our goal in sharing this information is to help you protect your “bike”, as it were, and be more confident in doing so.
Curious to learn more? One of these might be useful for you:
https://www.edureka.co/blog/web-scraping-with-python/
https://www.webharvy.com/articles/what-is-web-scraping.html
https://blog.hartleybrody.com/web-scraping/
Image –> shmoocon